Nonlinear runs tend to require anything from tens of iterations to thousands of iterations to complete. Reducing the number of iterations to convergence and reducing the time per iteration will speed up a run.
In this article we’ll discuss some ways to speed up iterations and leave reducing the time per iteration to a subsequent article.
Introduction
Every iteration in a non-linear analysis:
- updates the stiffness matrix (Assembly in Marc terminology)
- solves the static equation {F}=[K]{U} for {U}
- back-substitutes {U} to calculate convergence and results (Recovery in Marc terminology)
In other words, every iteration is the equivalent of a linear-static calculation. Speeding up any of the three sections will result in better run-times.
Note: Marc has had a method to solve in parallel for a really long time, but it was not so easy to set up the required third-party software in Windows (or Linux). It was also not that simple to get an efficient split in the workload. This method is DMP (Distributed Memory Parallel). In recent years, Marc also added SMP (Shared Memory Parallel) which is a lot easier to use as there is no set-up required. Performance improvement is also more predictable and reliable. For this reason, no mention of DMP will be made.
Memory, Memory, Memory
The most important way to ensure that Marc solves in a reasonable time is to ensure that the model fits in memory. This requires a solver with as much RAM as possible and also an Analyst that does not attempt to build the largest models possible.
To see if the memory is enough, open task manager and monitor memory usage of Marc.exe. If it comes close to the RAM in the machine, it’s time to upgrade the RAM or build more efficient models.
Faster Assembly and Recovery
Most solvers (PCs and Laptops) today have at least four CPU cores. Making use of the extra processing power can reduce runtime significantly.
Assembly and Recovery performance can be improved by running these in parallel. This is available from Marc 2013.1 onwards. This feature does require additional licenses, but is included for clients on the token system. The additional amount of tokens required is pretty reasonable.
Figure 1 shows where to activate parallel Assembly and Recovery in Mentat.
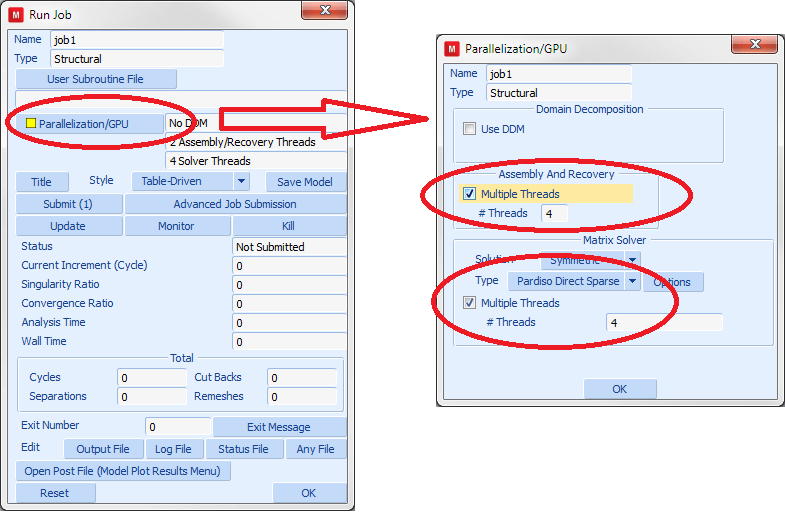
Figure 1: Activating Parallel settings in Mentat
Matrix Solvers
Marc has a number of different solvers that can be used to find the solution of the equation {F}=[K]{U}.
Some solvers support parallel solution. Parallel matrix-solution does not require any additional licenses though, so there is no reason not to use it on solvers that allows parallel solution. Figure 1 shows where to activate parallel matrix solution in Mentat.
The three important solvers in Marc are:
Multi-frontal sparse
This is the most capable solver in that it supports the most features. It happens to be the default Marc solver, and allows parallel execution. It is usually slower than the Pardiso solver.
It also allows GPU (Graphics Processor Unit) acceleration on NVidia graphics hardware, but this requires a special license. Unfortunately, the only GPUs that are capable of improving runtime are the Tesla cards, the Quadro k6000 and possibly the GeForce Titan. No ATI or Intel card is supported at this point in time, and all other NVidia cards will be too slow. My experience is that spending the money on a high clock-speed and higher core-count processor instead of one of these GPUs will yield better results for a given price-point.
Pardiso direct-sparse
The Pardiso solver is a great replacement for the multi-frontal sparse solver. It is nearly as capable while being faster. It also allows parallel execution. A really large test-model has shown a speed-up of 11 times on a 16-core solver machine when compared to a single-CPU run on the same machine.
CASI iterative
Iterative solvers uses a guess for the solution to {F}=[K]{U}. It then uses the guess to improve the guess. This process repeats until the convergence criteria are met. Note that these iterations do not have anything to do with the nonlinear equations.
The up-side to iterative solvers is that they require significantly less memory than the direct methods. The down-side is that they are only efficient on well-behaved solid-element meshes (somewhat over-simplified).
Which solver to use:
If the model contains only solid elements, the CASI solver is often the most efficient. Try it for an iteration or two and compare with the runtime of the Pardiso direct-sparse solver.
For other models, I’d suggest starting with Pardiso set to run parallel with as many cores as the solver has. Do not count “hyper-threads”. Only if Pardiso reports problems (almost never), switch back to multi-frontal sparse (parallel of course).
Conclusions and Recommendations
For efficient solution of Marc models, ensure that your solver has enough RAM.
Ensure that you run Marc 2013.1 or later to get the most out of parallel processing and choose the right solver and settings for the job:
- Use the Pardiso direct-sparse solver with as many cores as you have (this does not require additional licenses) as your default solver
- For solid-element models, try the CASI iterative solver to see if it can improve runtime over parallel Pardiso
- If you have the licenses available, activate parallel solution of Assembly and Recovery
Without any other changes, these can often reduce the runtime to less than 50% of the time obtained with the default settings.





